오늘은 조금 색다른 주제이다. 아마존에서는 머신러닝과 클라우드 활성화를 위해, 카메라 영상 기반의 자율주행을 간단히 실험해볼 수 있는 딥레이서를 2018년말에 출시했다. 이어 약 2년 동안 다양한 행사를 진행해 오고 있다. 개인적으로는 이런 잉여 프로젝트(?)를 진행할 수 있다는 점에서 아마존의 시도가 부러운 행사였다. 미국동부 region에서만 가능한 이 딥레이서는 지난 2년간 UI가 상당히 발전한 것도 특이사항이다. 초기의 여러가지 복잡할만한 UI가 조금만 익히면 빠르게 적응할 수 있도록 바뀌었다. 그래서 초기에 이 딥레이서를 했던 사람이라면 많이 변한 UI에 또한번 놀랄만하다.
AWS DeepRacer – 기계 학습을 시작하는 가장 빠른 방법
AWS DeepRacer Evo 차량에는 기존 AWS DeepRacer 차량, 기존 카메라와 스테레오 비전을 형성하는 추가적인 4메가픽셀 카메라 모듈, 스캐닝 LiDAR, 스테레오 카메라와 LiDAR 모두에 맞는 외판, 몇 가지 액세서�
aws.amazon.com
이 딥레이서는 클라우드 기반의 시뮬레이터 및 머신러닝 강화 학습기를 제공함과 동시에, 해당 훈련 모델을 실제 모형 자동차에 탑재시켜 오프라인으로 즐길 수도 있는데, 후자의 경우는 제법 큰 규모의 경주용 자동차 레인(자동차가 다닐 수 있는 길)이 필요해서 사실상 대회장에 가지 않으면 실물 자동차로 하기는 어려운 점은 있다. 그러나 온라인에서는 여전히 가상으로 대회에 참가할 수 있고, 여기서는 간단한 팁을 제공해본다.
실물 자동차를 그래도 구경은 해보자. 추가 키트(evo - 라이다 센서 등 추가 포함)가 나왔으며 아래는 순수 deepracer이다. amazon 사이트에서 deepracer로 검색하면 주문이 가능하긴 하다(현지 경유 해외 배송과 통관이라는 절차를 거쳐야하겠지만, evo를 합치면 가격은 거의 $600정도 한다.)



필자 같은 경우는 작년에 aws행사를 포함해 오프라인 대회에 두어번 참가한 경험이 있었다. 당시의 걱저은 처음에는 실물자동차와 온라인 시뮬레이터 학습 결과물이 잘 매칭되지 않을거라고 생각했는데, 생각보다 잘 작동해서 놀랬었다. 시뮬레이터에서 잘 되면 곧잘 실제 모형자동차에서도 안정되게 잘 작동한다(사례를 보면 모든 경우에서 그렇지는 않다) 개인적으로는 아마존이 어떻게 처음에 이것이 이정도까지 잘 안정되리라고 확신하고 이 사업을 진행한 것인지 신기했을 정도다.
각설하고, aws 로그인 후 아래를 누르면 딥레이서를 작동시킬 수 있는데, 초기에 비해서 개선된 UI를 만날 수 있다.
console.aws.amazon.com/deepracer/home?region=us-east-1#league
https://console.aws.amazon.com/deepracer/home?region=us-east-1#league
console.aws.amazon.com
핵심은 자동차를 먼저 만들고 (Your garage 메뉴), reward 함수와 옵션을 주어서 각 경주에 참여하고자 하는 코스에 맞게 훈련시킨 후에(Your models 메뉴) 해당 코스를 가지고 시행하는 virtual circuit에 참가하면 된다. 세부 내용은 각종 getting started 가이드를 따르면 된다. (불행히도 계속 조금씩 바뀌고 내용이 꽤 길긴 하다)
docs.aws.amazon.com/ko_kr/deepracer/latest/developerguide/what-is-deepracer.html
AWS DeepRacer이란 무엇입니까? - AWS DeepRacer
AWS DeepRacer이란 무엇입니까? AWS DeepRacer는 초보자든, 전문가든 상관없이 모든 사용자들이 강화 학습을 배우고 탐구하면서 자율 주행 애플리케이션을 실험하고 개발할 수 있는 통합 학습 시스템입
docs.aws.amazon.com
다만, 훈련시킬 시에는 1시간에 약 3.5$의 요금이 발생한다는 점은 미리 기억해둘 필요가 있다. 초기 참가시에는 소정의 (약 10시간 정도) 무료시간이 주어진다. aws에서 진행하는 워크샵에 참여하면 무료 계정을 쓸 수 있기도 하다.
1. 우선 자동차를 만들어보자

위 설정은 가장 보편적인 설정이라고 보면 된다. 어지간한 reward함수가 아니면 속도가 너무 높을시 학습이 잘 되지 않는다. 초기에는 maximum speed는 1.5도 좋다. 고수들은 3을 넘기도 하나본데, 학습을 수십시간 할 수도 있지 않을까 싶다(하지만 그렇게 비싸게 학습 시키기는 무리가 있다).
steering angle granularity도 3이 우선 좋다. 5면 조금더 다양한 각도로 틀 수 있으나 복잡도가 커지면 역시 학습이 어려워지기 시작한다. speed granulairty도 3정도로 잡아준다. 그렇게 모두 값을 정해주면 하단에 deepracer차량이 사용하는 action list가 나온다. 화면의 영상에 따라 이 deepracer가 각 action중 하나를 수행하게 되는 셈이다.
맨 처음에는 위에 추천한 옵션대로 차를 만들어 둔다.
(max steering angle도 작게 가져갈수록, 더 안정될 수 있는 점도 있으니, 코스에 따라 20도나 15도 설정도 나쁘지 않다)
2. 학습 모델을 잡자
학습 모델은 디폴트에서 조금씩 변형을 가하는 것이 좋지만 디폴트로도 우선 좋다. 학습 시간은 1시간에서 4시간을 조절해보면 아래와 같이 좋아지는 그래프를 볼 수 있다. 좋은 reward function을 설계해야만 강화학습에서 좋은 결과를 볼 수 있다. 그래서 처음 20분 정도 학습시에 이 reward증가세를 보고 학습을 지속할지 판단하는 것도 노하우이다. 아래 보면 2시간 30분간도 reward가 계속 잘 상승하는 것을 볼 수 있다. reward function이 좋지 않으면 이 수치 증가가 매우 더디며 횡보한다. (max speed가 높아도 잘 그렇게 된다)

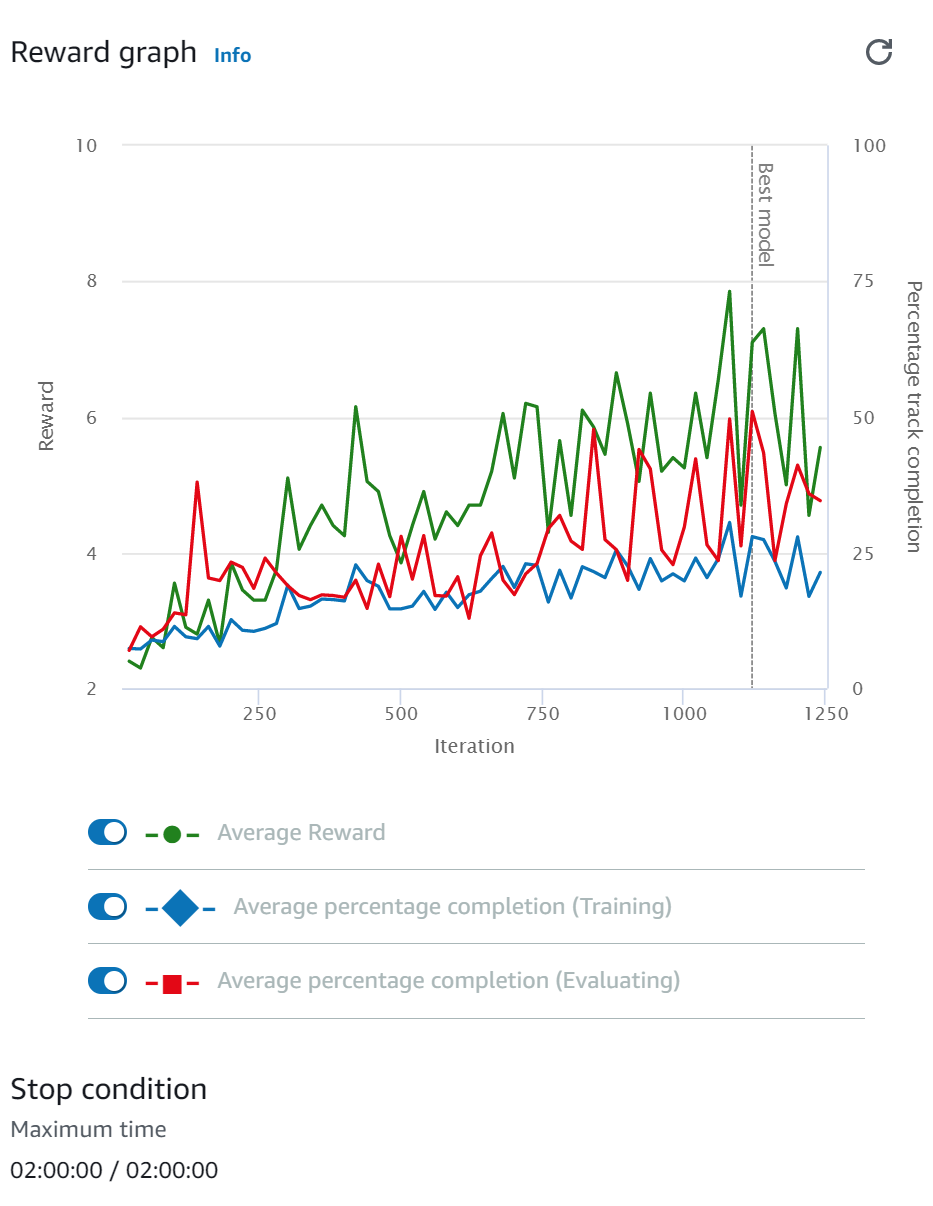
이 학습 모델의 핵심은 어떻게 잡으면 좋을까? deepracer는 입력된 영상을 위주로 학습한다. 그렇다면 내가 지금 보는 광경에 대해 어떻게 할지를 결정한다고 보면 된다.
1.0 m/s 를 최고 속도로 잡은 상태에서는 중앙선을 벗어나지 않게 하는 기본 reward함수도 잘 작동한다. 아마 복잡한 트랙에서 학습시킨다면, 해당 학습 모델은 거의 모든 경주 코스에서 유효할 수 있을 것이다(중앙선 영상은 모든 경우에 비슷할 테니까)
docs.aws.amazon.com/ko_kr/deepracer/latest/developerguide/deepracer-reward-function-examples.html
AWS DeepRacer 보상 함수 예제 - AWS DeepRacer
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
그러나 각 코스별 최상을 원한다면 아래 전략이 유효해보인다. 예를들면 아래는 2019 champion race course이다. 단지 도로 위의 카메라 영상만을 보고는 최고속의 부드러운 길을 미리 알 수 없으니 강제로 그 길을 미리 정해주는 것이다. 고속 주행을 위해서는 영상만으로 부족한 정보를 추가해주는, 유효한 전략이 아닐 수 없다.


실제로 1등 선수들의 주행 영상을 보면 거의 유사한 길을 가는 것을 알 수 있다. 저렇게 최적화 된다.
console.aws.amazon.com/deepracer/home?region=us-east-1#online/arn%3Aaws%3Adeepracer%3Aus-east-1%3A%3Aleaderboard%2Fsummit-season-2020-09-tt (aws 로그인 후, 오른쪽 하단의 각 선수별 Watch로 주행영상을 볼 수 있다)
이렇게 right, center, left lane에 waypoints 별로 가깝게 가면 보상해주는 reward function으로 만들 수 있는데 아래와 같다. (racingline)
github.com/scottpletcher/deepracer/blob/master/iterations/v2-RacingLine.md
scottpletcher/deepracer
AWS DeepRacer Experimentation. Contribute to scottpletcher/deepracer development by creating an account on GitHub.
github.com
여기에 필자의 경우에는 속도를 높게 유지하면 점수를 더 주는 함수도 반영해보았다. 그렇게 필자가 찍은 길과 함수이다. 그리고 다른 reward function들은 참조하기를 바란다.
github.com/neibc/deepracer/blob/master/deepracer4.py
neibc/deepracer
Contribute to neibc/deepracer development by creating an account on GitHub.
github.com
이 정도만으로도 max speed만 2이하로 학습시키면 중위권 이상에 들어가는 성적을 거둘 수 있다. 여러가지 시행착오 속에 깨달은 것은 다소 고속의 reward가 잘 올라가는 function을 찾았을시, 적절한 시간을 추가로 학습시키는 방법이 좋아보인다. 학습 파라메터 조율은 경험상 크게 도움이 되지 않았다. 그리고 어느정도 안정된 모델을 만들어 학습시켰으면, 윈도우 마우스 자동 매크로 툴로 여러번 모델을 race에 등록해 많이 시도하는 방법으로, 추가로 좋은 성적을 얻을 수 있지 않았을까 예상된다.
(max speed가 저속이 아니면 안정된 모델로 학습시키기 어렵기 때문에, 빠른 차량일수록 race evaluation을 여러번 시도하는 전략이 많지 않을까)
조금 다른 이야기를 해보면 딥레이서에 대해 보상함수를 바꿔가면서 새삼 깨달은 것이 있다.
무언가를 달성하기 위해서는 보상함수 안에 상호 보완 및 견제하는 이해관계가 필요하다는 점이다. 딥레이서가 길에서 벗어나지 않고, 최단거리로 주행하며, 코너링에서 안정적이고 또 빨리 가야한다는 원칙 모두에 대한 관계가 적절히 주어져야 최종 학습 후에 만족하는 결과가 주어진다. 어떤 것도 그냥 기대할 수는 없는 노릇이다. 어찌보면 사람 조직도 비슷하지 않을까 싶었다. 상벌의 체계와 부서간 견제 조율이 되어 평형을 이루게 하는 전략이 필요하지 않을까(사람은 모형차와는 물론 다른 부분이 있겠지만)
다음으로는 위의 복잡한 전략으로 조율되어야하는 지향점에 단순 시행착오로만 가려면 시간이 매우 오래걸린다는 점이다. 딥레이서의 경우 초기 reward function에서는 빠른 속도에 대한 보상보다는 정확한 길에 대한 학습을 먼저 1시간 정도 시키고, 점차로 속도에 대한 보상을 추가하며 단계적인 학습 전략을 거쳤을때 빠르게 원하는 궤도에 오를 수 있었다. 이런 단순게임에도 이런 원리가 대표되는게 놀라웠다. 간단한 목표로 시작해 다단계로 기대와 규칙을 올려서 학습하면 전체 학습 시간이 짧아진다
마지막으로는 이 경기에서 이기기 위해서는 전문지식 보다는 전문지식보다는, 빠르게 써보고 탐색하며, 시행착오를 겪은 다양한 경험자의 노하우를 습득해서 협업해야 진도가 빠르다는 점이다. 일단 툴에 익숙해지고 몇가지 시험을 해본 다음에는 여러가지 아이디어로 조금씩이라도 앞으로 나가면 경쟁에 유리해진다. 반복하다보면 big jump가 나오기도 한다. 실제 경기에 참여해보면 예컨데 머신러닝 전문가보다는, 빠르게 써보고 시행착오를 거쳐줄 투지가 있는 그룹을 이룬 20대~30대 초반의 젊은 친구들이 대회에서 좋은 성적을 거두는 것을 보면 이것이 fact로서 어느정도 입증된다고 보면 된다.
별도로 단계적 학습에 대해 조언해보면, 한번 학습한 모델을 Action 선택에서 clone할 수 있는데, 이렇게 하면 직전의 학습 결과물을 유지한상태에서 추가 학습시킬 수 있으므로, 학습 시간을 점진적으로 진행시키는 방법으로 삼을 수도 있다.
(해당 시점에서 계속 clone하면서 원하는 방향으로 조율해 나갈 수 있다)
딥레이서를 즐기실 분들에게 간단히 참고가 되었으면 좋겠다.
실제 차량에 모델을 심어서 주행하는 것에 대한 영상은 아래와 같다(2018년말 코스이다)
www.youtube.com/watch?v=MaSZfEmqMPs
european seeside circuit의 waypoint정보도 같이 실어보자.

'기타' 카테고리의 다른 글
| [휴대폰/패드 충전] 아이폰, 늦게 충전되는 문제를 둘러싼 충전기/케이블 이해 (0) | 2023.06.03 |
|---|---|
| [기타/전기플러그] 중국 쇼핑몰에서 산 220V 플러그가 헐거운데 그대로 쓰고계신가요? EU, US, 유로플러그, 돼지코 이야기 (2) | 2020.07.09 |
| [기타/iBeacon+Gyro] 자이로 센서(MPU6050)와 iBeacon(BLE)이 결합된 모듈 (0) | 2016.02.24 |
| [아두이노/기타] 초보자용 표준 세트 구성 제안 (0) | 2015.08.30 |



